MPI 入门笔记
周二的高性能计算导论课上提到了 MPI,小作业里也用到了,但是代码没太看懂。于是寻找了一份 MPI 的教程,中文翻译质量不错但必要时还是得看英文。
Basic Facts
-
MPI 是 Message Passing Interface 的简称
-
MPI 是一套标准,而实际的实现有许多
- 包括但不限于 OpenMPI(conv 集群上使用的)和 MPICH(教程中使用的)
-
MPI 为包括 Fortran77, C, Fortran90 和 C++ 在内的一系列编程语言提供了并行函数库
-
MPI 是进程 (process) 级并行,process 间内存不共享,与线程 (thread) 级并行不同
简单使用指南
基本要求
-
MPI 程序入口处应当调用
MPI_Init(int* argc, char*** argv)函数,实际上两个参数可以都填NULL。 -
MPI 程序结束前应当调用
MPI_Finalize()函数
进程间点对点通信
-
使用
MPI_Comm_size(MPI_COMM_WORLD, &world_size)来获取总进程数,保存在world_size中 -
使用
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank)来获取自己的进程编号,保存在world_rank中 -
使用
MPI_Send(const void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)来从一个 process 将数据发送到另一个 process- buf 是待发送缓冲区
- count 是发送数据数目
- datatype 是数据类型,MPI 内部自己的枚举类,与 C 原生类型存在对应
- dest 是目标 process 编号
- tag 是编号,只有 tag 对应的消息才会被接收
- comm 是组通讯器
-
使用
MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)来接收另一个 process 发来的数据- buf 是接收用缓冲区
- count 是最大接收数据数目
- 可以接收不超过这个数目的数据,如果超过会报错
- datatype 是数据类型
- source 是源 process 编号
- 可以用
MPI_ANY_SOURCE来接收所有源的消息
- 可以用
- tag 是编号,只有 tag 对应的消息才会被接收
- 可以用
MPI_ANY_TAG来接收所有任意 tag 的消息
- 可以用
- comm 是组通讯器
- status 是一个指向
MPI_Status结构体的指针,这次接收的更多信息会保存在这个结构体里- 可以用
MPI_STATUS_IGNORE来丢弃这个东西
- 可以用
-
MPI_Send和MPI_Recv是阻塞的,在一次发送 / 接收完成前不会继续向下执行 -
如果要发送自定义类型
- 将缓冲区强转
void * count填个数 *sizeof(MyType)datatype填MPI_BYTE
- 将缓冲区强转
-
MPI_Status结构体中记录了这些东西- 发送端的进程编号
- 消息的 tag
- 消息的长度(在指定类型后,元素个数也就可以知道了)
-
使用
MPI_Get_count(MPI_Status* status, MPI_Datatype datatype, int* count)来得到消息中的实际元素个数。 -
使用
MPI_Probe(int source, int tag, MPI_Comm comm, MPI_Status* status)来在不接收的情况下得到MPI_Status。- 如果不能确切知道实际待接收的元素个数,可以先
MPI_Probe拿到status,用MPI_Get_count算出个数,最后再MPI_Recv。此时就可以MPI_STATUS_IGNORE了。
- 如果不能确切知道实际待接收的元素个数,可以先
多进程同步
-
使用
MPI_Barrier(MPI_Comm communicator)来同步进程- 必须所有进程都执行到这一句才会继续执行下去,否则整个程序会卡住
-
使用
MPI_Bcast(const void *buf, int count, MPI_Datatype datatype, int root, MPI_Comm comm)来广播 / 接受广播数据。- 如果自己的进程编号是 root,则发送
buf,否则接收 MPI_Bcast使用一种树形广播算法来实现高效地广播- 简单的测试表明在单机的多个核上(即不涉及网络通信),
MPI_Bcast的效率大概是朴素的线性实现的 $\log N$ 倍,即 2 线程性能一致、4 线程性能 2 倍,8 线程性能 3 倍... - 它的广播行为和网络拓扑是否有关?换言之,对于异构集群,它是否会找比较“好”的广播路径?
- 简单的测试表明在单机的多个核上(即不涉及网络通信),
- 如果自己的进程编号是 root,则发送
-
使用
MPI_Scatter(void* send_data, int send_count, MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm communicator)来将一个缓冲区内的数据切分并将各段发送至其他进程。send_data是发送缓冲区send_count是待发送元素个数send_datatype是待发送元素类型recv_data是接收缓冲区recv_count是接收元素个数- 一般而言应当是
send_count的约数
- 一般而言应当是
recv_datatype是待接收元素类型- 一般和发送保持一致就可以了
root是发送进程communicator是组通讯器
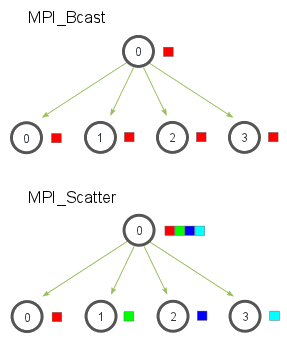
- 使用
MPI_Gather(void* send_data, int send_count, MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm communicator)来将各进程内的数据接收至 root 进程的一个大缓冲区内,与MPI_Scatter正好相反。由于函数签名一致,参数也不赘述了。
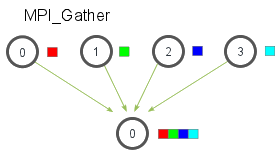
-
一个常见工作方式是这样的
- 0 号 process 是 root process,其他为 worker process
- root 准备好数据后将数据 Scatter 到各个 worker process 上去,由 worker 执行操作
- 用 Barrier 保证所有 worker 操作都执行完毕
- root 再将所有数据 Gather 回来
- 感觉这其实和 Map 很像XD
-
使用
MPI_Allgather(void* send_data, int send_count, MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, MPI_Comm communicator)来实现先 Gather 再 Bcast 的操作,即完成后所有 process 的缓冲区中都是相同的副本。除去没有 root(也不需要了)以外,函数签名和MPI_Gather一致,不再赘述。
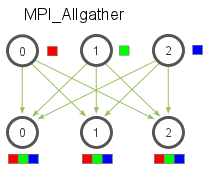
- 使用
MPI_Reduce(void* send_data, void* recv_data, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm communicator)来进行多进程数据的 reduce 操作。send_data是各个进程待 reduce 的发送缓冲区recv_data是 root 进程存放 reduce 结果的接收缓冲区count是缓冲区中元素个数datatype是元素类型op是 MPI 预先定义的 reduce 操作,包括最大/最小值、求和/求积、按位与/或、最大/最小值所在 rank 等。root是接收 reduce 结果的根进程communicator是通讯器
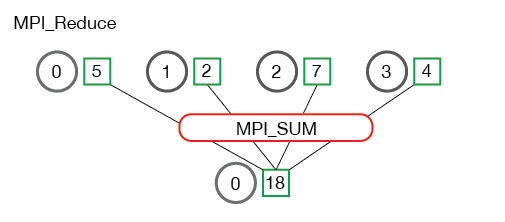
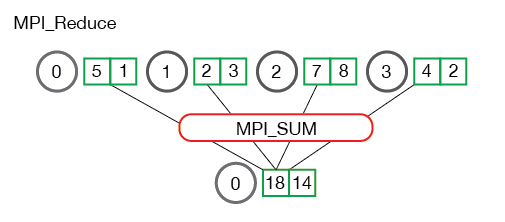
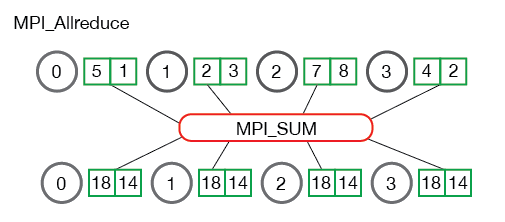
MPI_Allreduce和MPI_reduce的关系类似前面的 Allgather 和 gather,它将 reduce 后的数据发送给所有进程,因此签名为MPI_Allreduce(void* send_data, void* recv_data, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm communicator),没有 root,其余不变。
通讯器与组
-
一个“组”可以视为一个 process 的集合
-
一个通讯器对应一个组,用于组内 process 的相互通信
MPI_COMM_WORLD是包含所有 process 的全局通讯器- 使用
MPI_Comm_Rank(MPI_Comm comm, int *rank)来获取自己在通讯器内的 rank - 使用
MPI_Comm_Size(MPI_Comm comm, int *size)来获取这个通讯器中的线程数
-
使用
MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm* newcomm)来分割旧的 Communicator,创建新的comm是旧的通讯器color相同的进程会被分到同一个组(也即同一个新通讯器)内rank的顺序会被用于确定新的组内的 ranknew_comm是新创建的通讯器
例如,用 16 个 process 运行以下代码(只保留核心部分):
int world_rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int color = world_rank / 4;
MPI_Comm row_comm;
MPI_Comm_split(MPI_COMM_WORLD, color, world_rank, &row_comm);
int row_rank, row_size;
MPI_Comm_rank(row_comm, &row_rank);
MPI_Comm_size(row_comm, &row_size);
printf("World rank & size: %d / %d\t", world_rank, world_size);
printf("Row rank & size: %d / %d\n", row_rank, row_size);
原本是 (world_rank, 16) 的 process 在新的通讯器中会变为 (world_rank / 4, 16)
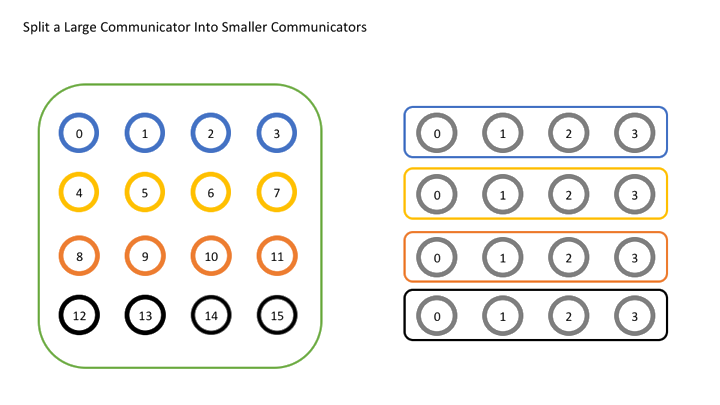
如果将 world_rank / 4 改为 world_rank % 4 那么将会由横向划分变为纵向划分,原理类似。
-
使用
MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm)和MPI_Comm_create_group(MPI_Comm comm, MPI_Group group, int tag, MPI_Comm *newcomm)都可以由一个组创建新的通讯器。- 没有很明白区别
-
MPI_Group可以执行交、并等集合运算
实话说,教程里这部分过于简略,基本上没看懂。
听去年选课的同学说,课上实际使用 MPI 的时候,一般不需要分组创建通讯器,只需要 MPI_COMM_WORLD 一把梭即可,所以这里也不再深究了。
杂项
- 使用
MPI_Wtime()计时- 返回 1970-1-1 到现在为止的秒数,也即 UNIX 时间戳