Introduction Note: MPI
In Tuesday’s Introduction to High-Performance Computing class, MPI was mentioned, and it was also used in a small assignment. However, I didn’t fully understand the code. So, I found an MPI tutorial. The Chinese translation is of good quality, but it’s still necessary to refer to the English version when needed.
Basic Facts
-
MPI stands for Message Passing Interface.
-
MPI is a standard, and there are many implementations.
- These include but are not limited to OpenMPI (used on the conv cluster) and MPICH (used in the tutorial).
-
MPI provides parallel function libraries for a series of programming languages, including Fortran77, C, Fortran90, and C++.
-
MPI is process-level parallelism, where memory is not shared between processes, unlike thread-level parallelism.
Quick Usage Guide
Basic Requirements
-
The MPI program should call the
MPI_Init(int* argc, char*** argv)function at the entry point. In practice, both parameters can be set toNULL. -
The MPI program should call the
MPI_Finalize()function before exiting.
Point-to-Point Communication Between Processes
-
Use
MPI_Comm_size(MPI_COMM_WORLD, &world_size)to get the total number of processes, which is stored inworld_size. -
Use
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank)to get the process’s own rank, which is stored inworld_rank. -
Use
MPI_Send(const void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)to send data from one process to another.bufis the send buffer.countis the number of data items to send.datatypeis the data type, an internal MPI enumeration that corresponds to native C types.destis the rank of the destination process.tagis the message tag; only messages with the corresponding tag will be received.commis the communicator.
-
Use
MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)to receive data from another process.bufis the receive buffer.countis the maximum number of data items to receive.- It can receive up to this number of items; exceeding it will cause an error.
datatypeis the data type.sourceis the rank of the source process.MPI_ANY_SOURCEcan be used to receive messages from any source.
tagis the message tag; only messages with the corresponding tag will be received.MPI_ANY_TAGcan be used to receive messages with any tag.
commis the communicator.statusis a pointer to anMPI_Statusstructure, which stores additional information about the received message.MPI_STATUS_IGNOREcan be used to discard this information.
-
MPI_SendandMPI_Recvare blocking; they will not proceed until the send/receive operation is complete. -
To send custom types:
- Cast the buffer to
void *. - Set
countto the number of items multiplied bysizeof(MyType). - Set
datatypetoMPI_BYTE.
- Cast the buffer to
-
The
MPI_Statusstructure records the following:- The rank of the sending process.
- The message tag.
- The length of the message (the number of elements can be determined after specifying the type).
-
Use
MPI_Get_count(MPI_Status* status, MPI_Datatype datatype, int* count)to get the actual number of elements in the message. -
Use
MPI_Probe(int source, int tag, MPI_Comm comm, MPI_Status* status)to obtainMPI_Statuswithout receiving the message.- If the exact number of elements to receive is unknown, you can first use
MPI_Probeto getstatus, useMPI_Get_countto calculate the number of elements, and then useMPI_Recv. At this point, you can useMPI_STATUS_IGNORE.
- If the exact number of elements to receive is unknown, you can first use
Multi-Process Synchronization
-
Use
MPI_Barrier(MPI_Comm communicator)to synchronize processes.- All processes must reach this point before proceeding; otherwise, the program will hang.
-
Use
MPI_Bcast(const void *buf, int count, MPI_Datatype datatype, int root, MPI_Comm comm)to broadcast/receive broadcast data.- If the process’s rank is
root, it sendsbuf; otherwise, it receives. MPI_Bcastuses a tree-based broadcast algorithm for efficient broadcasting.- Simple tests show that on a single machine with multiple cores (i.e., no network communication), the efficiency of
MPI_Bcastis approximately $\log N$ times that of a naive linear implementation, i.e., 2 threads perform the same, 4 threads perform 2x, 8 threads perform 3x... - Does its broadcasting behavior depend on the network topology? In other words, for heterogeneous clusters, will it find a "better" broadcast path?
- Simple tests show that on a single machine with multiple cores (i.e., no network communication), the efficiency of
- If the process’s rank is
-
Use
MPI_Scatter(void* send_data, int send_count, MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm communicator)to split data in a buffer and send segments to other processes.send_datais the send buffer.send_countis the number of elements to send.send_datatypeis the type of elements to send.recv_datais the receive buffer.recv_countis the number of elements to receive.- Generally, it should be a divisor of
send_count.
- Generally, it should be a divisor of
recv_datatypeis the type of elements to receive.- It’s usually the same as the send type.
rootis the sending process.communicatoris the communicator.
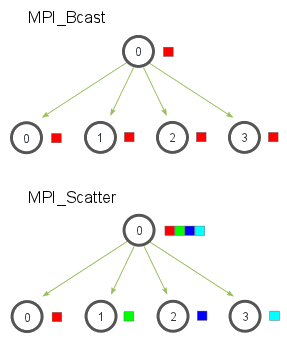
- Use
MPI_Gather(void* send_data, int send_count, MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm communicator)to gather data from all processes into a large buffer in the root process, the opposite ofMPI_Scatter. Since the function signature is the same, the parameters are not repeated here.
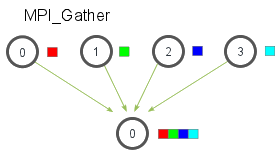
-
A common workflow is as follows:
- Process 0 is the root process, and the others are worker processes.
- The root prepares the data and scatters it to the worker processes, which perform the operations.
- Use
Barrierto ensure all worker operations are complete. - The root gathers all the data back.
- This feels similar to Map, XD.
-
Use
MPI_Allgather(void* send_data, int send_count, MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, MPI_Comm communicator)to perform a gather followed by a broadcast, so that all processes have the same copy of the data in their buffers. The function signature is the same asMPI_Gather, except there is noroot(it’s no longer needed), so it’s not repeated here.
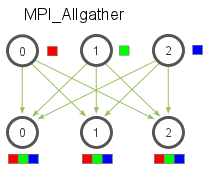
- Use
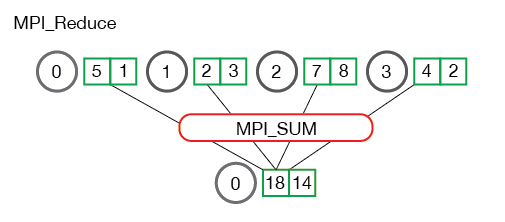
MPI_Reduce(void* send_data, void* recv_data, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm communicator)to perform a reduce operation on data from multiple processes.send_datais the send buffer for each process’s data to be reduced.recv_datais the receive buffer in the root process for the reduced result.countis the number of elements in the buffer.datatypeis the element type.opis the predefined reduce operation in MPI, including max/min, sum/product, bitwise AND/OR, and the rank of the max/min value.rootis the root process that receives the reduced result.communicatoris the communicator.
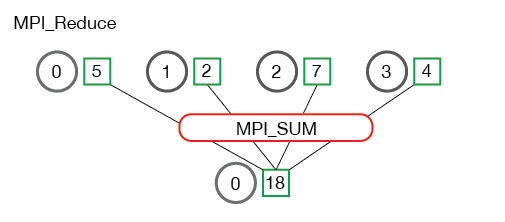
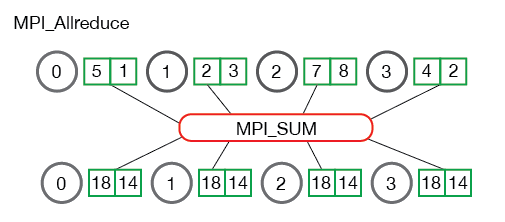
MPI_Allreduceis toMPI_reducewhatAllgatheris togather. It sends the reduced data to all processes, so the signature isMPI_Allreduce(void* send_data, void* recv_data, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm communicator), with noroot, and the rest remains the same.
Communicators and Groups
-
A "group" can be considered a collection of processes.
-
A communicator corresponds to a group and is used for communication between processes in the group.
MPI_COMM_WORLDis the global communicator that includes all processes.- Use
MPI_Comm_Rank(MPI_Comm comm, int *rank)to get the rank of the process within the communicator. - Use
MPI_Comm_Size(MPI_Comm comm, int *size)to get the number of processes in the communicator.
-
Use
MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm* newcomm)to split the old communicator and create a new one.commis the old communicator.- Processes with the same
colorwill be grouped into the same new communicator. - The order of
rankwill be used to determine the new rank within the group. new_commis the newly created communicator.
For example, run the following code with 16 processes (only the core part is retained):
int world_rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int color = world_rank / 4;
MPI_Comm row_comm;
MPI_Comm_split(MPI_COMM_WORLD, color, world_rank, &row_comm);
int row_rank, row_size;
MPI_Comm_rank(row_comm, &row_rank);
MPI_Comm_size(row_comm, &row_size);
printf("World rank & size: %d / %d\t", world_rank, world_size);
printf("Row rank & size: %d / %d\n", row_rank, row_size);
Originally, the process with (world_rank, 16) will become (world_rank / 4, 16) in the new communicator.
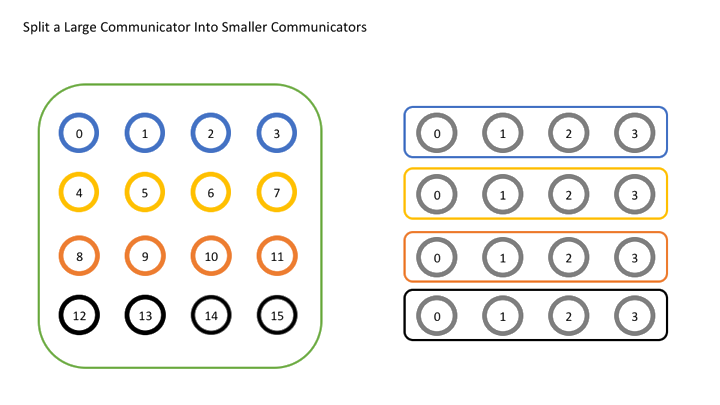
If world_rank / 4 is changed to world_rank % 4, the division will change from horizontal to vertical, with a similar principle.
-
Use
MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm)andMPI_Comm_create_group(MPI_Comm comm, MPI_Group group, int tag, MPI_Comm *newcomm)to create a new communicator from a group.- I didn’t fully understand the difference.
-
MPI_Groupcan perform set operations like intersection and union.
Honestly, this part of the tutorial is too brief, and I didn’t fully understand it.
According to students who took the course last year, when using MPI in class, you generally don’t need to create communicators by splitting groups; you can just use MPI_COMM_WORLD directly. So, I won’t delve deeper here.
Miscellaneous
- Use
MPI_Wtime()for timing.- It returns the number of seconds since 1970-1-1, i.e., the UNIX timestamp.